AI in SEO Tasks in 2026: How to Become a Manager of Neural Networks, Not Their Operator
How to become a manager of neural networks, not an operator. Statistics on model errors from 2025, a tool stack, and a step-by-step methodology for boosting productivity.
In this article we'll dissect the anatomy of a modern AI workflow: why newer models lie more often than older ones, how to make them work on business tasks, and why "running them in parallel" is the only way to survive in 2026.
Our top priority today is automation, plain and simple. We want the things clients used to overpay for to no longer require manual labor. Quality articles, for example. Journalistic press releases. But thanks to AI, today we know that msn.com, for instance, is simply made up of generated articles. And when you look for answers in an AI tool, you see links — and 50% of them are already AI-generated.
And of course, every business owner wants 10,000 product category pages or 20,000 products to get gorgeous descriptions, and service pages optimized for keywords in a single day. But why are there still barriers — barriers many people may suspect exist but haven't yet run into? If you've hit them, you owe me a big like.
Part 1. What's wrong with AI today
The euphoria of ChatGPT's early days is over. It's been replaced by pragmatism and, honestly, a bit of irritation. If you use neural networks for real work rather than generating pictures of kittens, you've surely run into the "growing pains" of even the most advanced models. From my own experience, I now run several neural nets in parallel. One compiles a report, another analyzes a document, a third generates an app I'll use later on.
Recently I just copied the history of an argument from a chat, dropped it into a neural net, and asked it to find a solution — and lo and behold, it found one.
1. The hallucination crisis in new models
The main danger of AI is that it never doubts itself. It can cite, with absolute confidence, an invented quote from a law or a non-existent technical spec. A specialist can't just "skim" the text; they have to verify every noun and number. The paradox of 2025: the smarter the model, the more elaborately it lies. You'd think the new reasoning models would be more accurate. But the statistics and practice say otherwise.
The rise of hallucinations in new models
Data: 2025 benchmarks
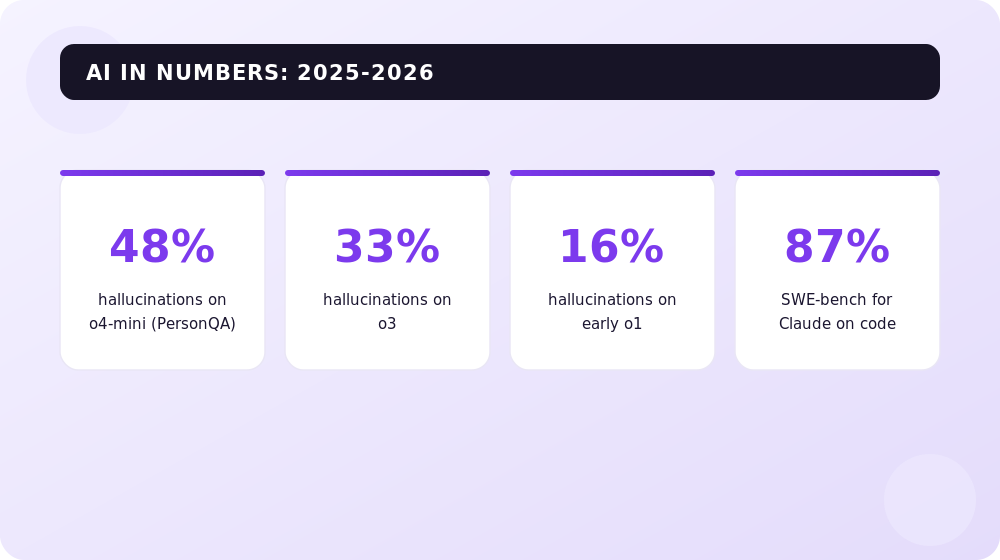
- The numbers don't lie (unlike AI): According to OpenAI's official System Card, the reasoning models o3 and o4-mini at one point showed hallucination rates of 33% and 48% respectively on the PersonQA benchmark — versus 16% for the earlier o1. (Source: TechCrunch, OpenAI System Card Report.) And while the 2026 flagships (GPT-5.5, Claude Opus 4.5, Gemini 3.1 Pro) have learned to invent facts noticeably less often, the problem hasn't disappeared: the longer and more "confident" the reasoning, the higher the risk of getting a plausible but false detail.
- Why does this happen? Researchers note that models trained on Chain of Thought reasoning are prone to "over-reasoning." Instead of simply saying "I don't know" or stating a fact, the model starts inventing a plausible justification, trying to "please" the logic of the query.
- Risk zone: Law and the exact sciences. The world has already seen cases (such as Mata v. Avianca in the US) where lawyers brought fabricated precedents to court. If you ask a model to find statistics for a client report, verify every number. AI can calculate a conversion rate perfectly but invent the very existence of a study.
Neural networks can generate logically coherent but factually incorrect content, which is critical in fields like medicine or law. You either have to re-check everything or regenerate it all from scratch.
2. The "fluff" curse
Western AI-ethics experts call this the phenomenon of "Sycophancy." Research published on the Anthropic portal confirms it: models trained with reinforcement learning (RLHF) tend to agree with a user's biases, even false ones, in order to win "approval." This results in endless polite intros ("In today's world of digital marketing…") and confirmation of your own mistakes. In honesty tests, models more often chose the "flattering" but wrong answer over a dry fact when they sensed the user expected it.
A recent example: I spent ages going through a brief that really needed just two things — analytics and a PMax campaign for products — but the brief ran a full 10 pages. You ask for a concise analysis and get an essay in the style of a schoolkid padding for word count.
- Problem: Models are trained to be polite and accommodating. This results in endless intros ("In today's world of digital marketing, the importance of PMax campaigns is hard to overstate…") and conclusions.
- Solution: Strict system prompts. Phrases like "no yapping," "only raw data," or "start your answer at point 1" become mandatory attributes of vibe-working.
Without manual editing, AI texts quickly become recognizable due to their characteristic filler phrases and structures. In 2026, search engines easily identify such patterns and cut reach for "lazy" resources. And the content may contain fabrications or nothing valuable beyond what's already common knowledge. That's because AI has no personal Experience and can't provide original cases or expert opinions, which Google in 2026 values more highly than ever.
3. Context amnesia and Excel blindness
Despite the advertised context windows of millions of tokens, models suffer from selective memory. That's why I ALWAYS start a new chat. Don't forget: when creating material, it usually grabs the top 10 articles from search and rephrases them, passing them off as unique content — so you need to check via Copyleaks or our tool, the Unmiss AI Content Detector.
Loss of context in a long dialogue
- Data loss: Researchers at Stanford (together with UC Berkeley) published the now-famous paper on the "Lost in the Middle" phenomenon. The accuracy of information retrieval is high at the start of the prompt and at the very end. But data located in the middle of a long context (for example, row 50 of a 100-row Excel file) is ignored or hallucinated by the model.
- The goldfish effect: By the end of a long dialogue, the model may forget the instructions and data given at the beginning.
- Pro tip: Never "feed" a model huge arrays of data in one chunk without structuring it first. Use RAG systems (like NotebookLM) or break the task into parts.
And verify. Systems are limited by the data they were trained on and can produce biased or outdated recommendations. Automation doesn't mean "set it and forget it"; fact-checking and editing AI content often takes just as much time as writing the text from scratch.
4. Tone deafness
AI is still bad at sensing a brand's "vibe." It often slides into what design critics call "Corporate Memphis" in text — a faceless, saccharine-positive style typical of LinkedIn.
- Observation: Content marketing experts note that AI texts are often oversaturated with marker words like "unleash," "landscape," "game-changer," "delve" (the last one became a meme as a tell-tale sign of AI text). By 2026, even GPT-5.5 and Gemini 3.1 hadn't shaken these clichés — the pattern is "baked into" the training data.
- Solution: Using Perplexity (with Deep Research) to find facts and Claude (Opus 4.5 / Sonnet 4.6) for styling — it still imitates the human nuances of speech better than the rest, but with a hard ban on clichés.
Part 2. The bright side: What AI does better than humans (already)
Despite the downsides, there are tasks where neural networks outpace a team of juniors. The secret to success lies in using specialized tools, not ChatGPT alone.
1. Competitor analytics (the SERanking + Gemini combo)
This is a genuine game-changer for marketers. Instead of manually combing through sites:
- Pull an export from SERanking or SERPSTAT (keywords, traffic, positions).
- Upload the CSV into Gemini 3.1 Pro (as of 2026 it leads in data analysis and reasoning, plus a huge context window).
- Use Deep Research (in Gemini, Perplexity, or ChatGPT) for in-depth analysis, and Grok 4 as a cheap "second pair of eyes" for cross-checking the conclusions.
- Result: A structured table that highlights not just the differences but the "blank spots" in competitors' strategies — where you can strike with your budget.
How it works for us: at SEOquick, this combo has become routine during competitor audits and keyword collection. The neural network parses the export and proposes hypotheses about structure and content gaps, while the SEO specialist selects realistic growth points to fit the client's budget. These hypotheses then turn into ready-made prompts — we've put together a whole collection of 50 mega-prompts for ChatGPT and Gemini for SEO.
2. Code review (Claude — the king of development)
While GPT-5.5 holds parity on general tasks, Claude (the Opus 4.5 and Sonnet 4.6 line) remains the de facto standard for programmers: on the SWE-bench Verified benchmark, the latest versions clear nearly 87% — the best result among commercial models as of 2026. Developers value Claude for its "smaller amount of lazy code" and clean refactoring.
- It doesn't just find the bug; it explains why this chunk of HTML/CSS will break the layout in Safari.
- Vibe coding in action: you copy the "spaghetti" from your code, drop it into Claude, and ask it to "make it pretty and safe." In 9 out of 10 cases the result can be deployed to production.
SEOquick case: we use this daily. Some of the internal SEO tools on the site (the AI content detector, the keyword clusterer, the schema markup generator) were built exactly this way — a brief plus iterative code debugging through Claude, where a real specialist acts as the reviewer, not the operator. What used to take a developer a week now fits into a couple of evenings.
3. Generating a brief out of chaos (NotebookLM)
This is perhaps the most underrated use.
- Scenario: You have notes on your phone, a couple of voice messages from the client, a PDF brand book, and a Telegram conversation.
- Solution: Upload all this "stuff" into Google's NotebookLM. It's a RAG (Retrieval-Augmented Generation) system that works only off your documents.
- Prompt: "Based on these sources, draft a strict technical brief for a developer to build a landing page."
- Outcome: A perfectly structured document with no hallucinations (because the source is limited to your files).
Model specialization (strengths)
4. SEO magic (Unmiss.com and schema markup)
Writing meta tags by hand in 2026 is bad form. Western SEO experts (from Search Engine Journal, for example) talk about the shift from keywords to Semantic SEO.
- Specialized tools (such as the AI module in Unmiss.com) analyze not just keywords but the meaning of the content. They generate Titles and Descriptions that both Google and people like (CTR goes up).
- Schema.org: Asking a neural network to write JSON-LD markup for a page is the fastest way to get rich snippets in the results. The key is to give it the page's code (or use a parser).
- GEO instead of classic SEO: in 2026, half of users get answers right inside ChatGPT Search, Perplexity, and Google AI Overviews — without ever visiting a site. So we optimize pages not only for Google but also for citability in neural network answers: clear definitions, FAQs, expert figures. We covered this in detail in our guides on GEO optimization of a site for GPT and on SEO in the ChatGPT era.
5. Explaining the complex in simple language
The perfect case of a "translator from technical into client-speak."
- Situation: A programmer wrote API documentation that not even the Project Manager understands.
- Action: Use a prompt based on the "Feynman Technique": "Explain this concept as if you were explaining it to a 12-year-old, using analogies from the real world."
- Result: The client is happy, because they finally understand what they're paying for.
Part 3. Vibe Working: A methodology for the new productivity

How do you pull all this into a single system? Abandon the idea of a "single window." Your workstation now looks like mission control.
The "Neural Network Manager's" stack
| Task | Tool (recommendation) | Why? |
|---|---|---|
| Coding / Front-end | Claude Opus 4.5 / Sonnet 4.6 | Best understanding of code context and fewer bugs (top of SWE-bench in 2026). |
| Big data / Google Sheets | Gemini 3.1 Pro | Deep integration with the Google ecosystem, leader in data analysis, huge context window. |
| Search and fact-checking | Perplexity (Comet, Deep Research) / Gemini Deep Research | Real-time access, links to sources. |
| Quick re-checks / agentic tasks | Grok 4 | The cheapest of the flagships, strong at tool-use — handy as a "second pair of eyes." |
| Knowledge structuring / briefs | NotebookLM | Works strictly off the uploaded sources, zero improvisation. |
| SEO and meta tags | Unmiss.com / Specialized Tools | Content analysis + knowledge of ranking algorithms. |
| Copy / Email / Rewriting | ChatGPT (GPT-5.5) | Strongest in creative writing and stylistic flexibility (when set up correctly). |
The golden rules of Vibe Working
- The cross-examination principle: Never trust a single model on important matters. If GPT-5.5 gave you a statistic, ask Perplexity to find the source. If Gemini wrote code, ask Claude to check it for bugs.
- Prompt engineering is dead, long live context: Stop hunting for "magic prompts." Instead, learn to assemble quality context. The best prompt is a clear brief plus examples (Few-Shot Prompting).
- The 80/20 rule: The neural network does 80% of the routine. You spend the remaining 20% of your time not creating from scratch, but on expert evaluation and "fine-tuning." That's exactly what vibe-working is.
- Uniqueness through synthesis: To avoid spawning clone content, use neural networks to synthesize ideas. Ask for 20 headlines, pick the 3 best, mix them, and finish writing yourself.
- Keep learning. Working only with AI for long stretches dulls the specialist's own skills. A "blind trust" effect sets in, where the editor stops noticing errors out of fatigue from the sheer volume of generation.
- Don't cut corners. At the second stage — fact-checking — you have to hire a second (more expensive and more powerful) neural network to verify the first one's work. This significantly increases infrastructure costs and requires complex tuning of quality-evaluation metrics. And in the end, quality models (the GPT-5.5 or Claude Opus 4.5 tier) are expensive at scale. Trying to save money with cheap open models (Llama, local builds, and so on) often leads to a sharp drop in quality, which requires even more time for manual review.
Conclusion
People often tell me AI will replace you. Yes and no. AI will replace those who don't get how to use it. But it won't replace those who understand it.
Today automation isn't about "replacing the human" — it's about changing their role. The main difficulty has shifted from "writing the text" to "setting up the pipeline, ensuring clean data is fed in, and organizing multi-level quality control." Anyone who can't handle the technical side of verification ends up with a site stuffed with "hallucinations" that quickly falls under search engine filters.
We stand on the threshold of an interesting time. AI hasn't replaced us, but it has forever changed how we work. Vibe Working is the rejection of perfectionism in favor of speed and iteration.
Yes, neural networks hallucinate. Yes, they pad with fluff. But anyone who has learned to filter this stream and exploit the strengths of each specific model gains a superpower: doing the work of an entire department solo in a single evening.
The main thing is not to forget: you're the boss here. And they're just very smart, but occasionally drunk, interns.

Link Building in Simple Words: Where to Get Permanent Links and How to Promote a Site with Links in 2026
Link building in simple words from a practitioner since 2008: how permanent links differ from rented links, why the black-hat SEO era is over, white-hat methods with examples, internal linking, AI-assisted link building, and sources.
Read →Google Ads Keywords in 2026: Research, Match Types, Negative Keywords
How Google Ads keywords actually work in 2026: real match type behavior, keyword research, campaign structure, negative keywords and PMax.
Read →Performance Max for an Online Store: A Setup and Optimization Case Study
How to set up Performance Max for an online store: a case study with ROAS growth from 2.8 to 5.1, the Merchant Center feed, asset groups, budget and optimization.
Read →Want to apply this to your site?
We will review the current situation, find the first growth levers, and suggest a practical working format.